
Cyber
January 25, 2023
Techniques for Effectively Securing AWS Lake Formation
AWS Data Lake Services
A couple months ago, we received a request from one of our enterprise financial clients looking to build their internal data lake capabilities. The client wanted to know more about security best practices related to the AWS data lake management tool, AWS Lake Formation, and asked our team for help. One of our principal security consultants specializing in cloud got to work, preparing an overview of critical security considerations when architecting a data lake system. We thought this overview was too good to keep a secret, and there isn’t a lot of public information about data lake security, so here is a contribution from us!
What is a Data Lake and What Does It Do?
By AWS’s definition, a data lake is a, “a centralized repository that allows you to store all your structured and unstructured data at any scale.” Consider a situation in which an organization needs to retain a large blob of data that has various levels of sensitivity and that needs to be accessed by various individuals. This is where a data lake becomes useful.
Going a bit deeper, data lakes are huge data storage “databases”, created with the primary objective of storage, but they must also be able to be searched and queried. Data lakes enable computation tasks (ML/AI, business analytics, etc.) to be performed on data in storage. The data lake provides access to the data, but the computational tasks are done by other services. Data lakes generally don’t have as robust query capabilities as a relational database.
An example might be a large store of employees' personal data that contains details such as names, dates of birth, and paystub information. Different individuals may need to have access to different types of data. If this data is all in one location, creating a seamless solution can be difficult, as can scaling that solution over time.
What is Involved in Securing a Data Lake?
Data lakes are a technology that is fundamentally enabled by cloud services although similar capabilities can be built in house/on-premises. The security of the data lake is focused on architecting for integration with other services, since that is what makes the data valuable and provides access vectors creating security issues.
This article is specific to AWS Lake Formation, which is AWS’s data lake management tool, although you can see there are several services that are required to make a data lake work. Similar concepts should be considered for other cloud providers of data lake technology, but the services and implementation will differ.
Lake Formation is an AWS service that provides a management layer over this data. It allows administrators to create databases to manage data within a data lake, to create and manage user permissions and to leverage several services to either import data or have data made accessible to end users.
Several services are used to accomplish these tasks:
- Amazon S3 is used as the underlying storage mechanism. It is the location of the files and data that make up the data lake.
- AWS Lake Formation is used for administrators to manage the data lake.
- AWS Glue is used to data crawl and for ETL jobs. A customer can take data from one location, make any required data transformations, and store the data in S3.
- Amazon EMR, Amazon Athena and Amazon Redshift are end consumers of data that is present within a Lake Formation data lake. End users who use these services can query data from within the data lake and have only the data that they have access to be returned via the data lakes permission configuration.
AWS S3
Best Practices
AWS S3 is a widely used service that has great public documentation for security considerations. Most automated AWS configuration tools cover the basic test cases. Most security in S3 can be configured directly by enabling security options:
- Block public access should be enabled across the entire account.
- Each bucket should not have any public objects or an open bucket policy.
- Objects in each S3 bucket should be encrypted.
- Encryption of data in transit should be enforced.
More information about these options can be found at the following link: https://docs.aws.amazon.com/AmazonS3/latest/userguide/security-best-practices.html
Lake Formation Specific Considerations
S3 Data Locations
When an administrator configures a data lake, they must register an S3 location. Once the location has been set, the data at that location can be used with data catalogs. An example of a data location follows:
s3://bucketname/hr/employees/canada
When a location is configured, that location and everything under it are added to the data lake. This data includes all the files that are present within the S3 file structure. When a new data location is being created, the service console prompts users to review existing location permissions for that location. Conducting this review is strongly recommended because these settings can easily be misconfigured.
S3 Data Location and Data Access Permissions
Once a location has been registered, an administrator can restrict access by using data location and data access permissions.
Data location permissions are granted to principals (e.g., IAM users or roles) via a grant command such as the following:
aws lakeformation grant-permissions --principal DataLakePrincipalIdentifier=arn:aws:iam::111122223333:user/datalake_user1 --permissions "DATA_LOCATION_ACCESS" --resource '{ "DataLocation": {"ResourceArn":"arn:aws:s3:::/bucketname/hr/employees/canada"}}'
Once a given user has DATA_LOCATION_ACCESS permission to a given location, they can create a metadata database or a table at that location (assuming they have the proper Lake Formation permissions to do so). The security impact of this access is that if a given principal has DATA_LOCATION_ACCESS for a given location, they have a path to access all the data in that location (and its child directories).
Principals can also be granted data access permissions (SELECT, INSERT, DELETE). These permissions are covered in the Lake Formation section.
Common Misconfigurations
- Data locations overlap (e.g., s3://bucket/a/b/c is configured in one data lake, while s3:///a/b/ is configured in a different data lake with more lax permissions).
- Data locations that have excess data are configured (e.g., a location to which unauthorized users are allowed to write from outside the data lake).
- DATA_LOCATION_ACCESS permission is granted to a principal that should not have it.
- DATA_LOCATION_ACCESS permission is granted to a principal at the root of a bucket or at a prefix that is too high in the hierarchy.
- A principal has grantable permissions for a location that allows them to grant permissions to other users.
- Unregistered locations in a bucket can be accessed without access control by a user that has location access to the full bucket.
When Lake Formation is being configured for an S3 bucket or when a review that covers this configuration is being performed, it is important to have a clear folder structure and plan of data segregation. The following steps can be followed during a review:
- Obtain a directory structure of the S3 bucket that is being used for the data lake, with indicators for which groups of users should have access to which parts of the data structure.
- List all data locations that have been set up within the data lake
- Evaluate the data locations to determine whether there are any redundant locations (e.g., a/b/c and a/b) or locations that encompass too broad of a structure (e.g., the root of a bucket that contains a large amount of various data)
- Review data location permissions for the above locations, and ensure that the users with each permission should have that permission
- Identify any locations in the bucket that are not configured within the data lake
AWS Lake Formation
Permissions
Lake Formation has a very complex permission system. For any specific task that a customer performs, the customer needs to have both IAM and Lake Formation permissions. For example, when reading data from an S3 location, the customer needs to have the underlying S3 permissions as well as the SELECT data access permissions. They obtain the IAM permissions indirectly via the role that is attached to the data location in S3, and their principal needs to have read permission for that data.
Data Lake Administrators
Data lake administrators are a list of users within a data lake. These users have very privileged access, including full read access to all resources, full data location permissions, and the ability to modify permissions across the entire catalog.
The following two permissions are required to create a data lake administrator:
- lakeformation:PutDataLakeSettings
- lakeformation:GetDataLakeSettings
These permissions are given by the administrative access policy. As such, a user with this policy can be assumed to have implicit access to the data in the data lake. Unlike for other services in AWS, the data that is contained in the data lake may be particularly sensitive, so it is important to identify all possible users that have this permission.
In a normal configuration, it is common for an IT administrator to have full, unrestricted admin access to the AWS account. However, there may be regulatory or compliance reasons that this access may need to be limited in an account that has a sensitive data lake.
Database Creators
Database creators are users that have had the permission to create a database (https://docs.aws.amazon.com/lake-formation/latest/dg/lf-permissions-reference.html#perm-create-database).
If a user has database creator permission and data location access for a given location, then they have implicit access to all the data at that location.
In general, the number of users that are allowed to create databases should be limited.
Data Access Permissions
Once a location has been added and a database created for that location, it is possible to define data permissions for databases and tables.
The following screenshot shows the permission types that can be defined for a given database. They include granting principals the ability to create a new table and to alter, drop, or describe tables. There is also an option to allow this principal to grant permissions to other users.
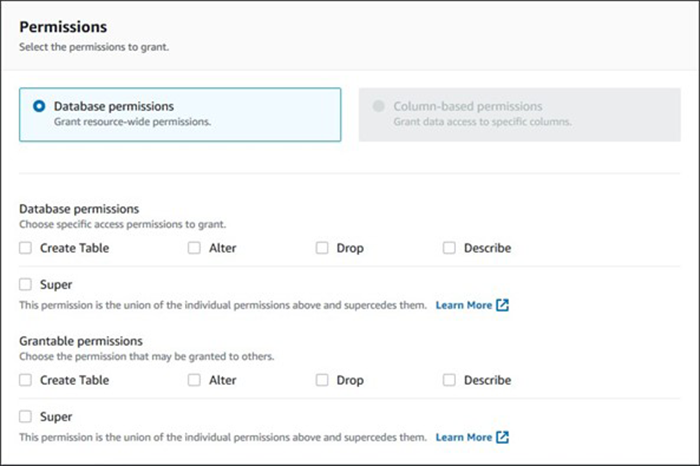
The following screenshot shows, for a given table, the possible permissions a principal can have. A user with select permissions can read data from the table, and a user with describe permissions can describe a table, for example.
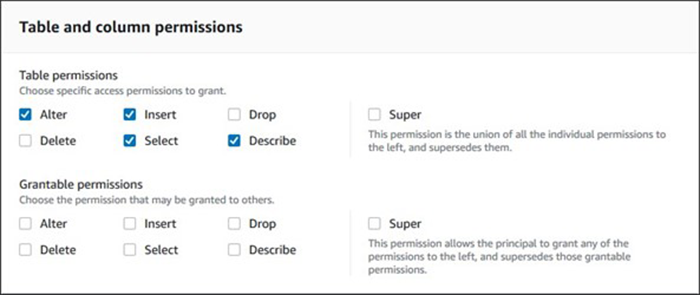
Generally, the principals defined here are services that integrate with Lake Formation. For example, if an administrator wants to configure Amazon Redshift to be able to read only from a Lake Formation table, they would create a role, grant it permissions to SELECT for a given table and then launch the Redshift cluster with that role.
It is also possible to set data filtering and column-specific restrictions, which can be used to further limit which data a user is able to access.
Common Misconfigurations
- An excessive number of Data Lake Administrators or Database creators exists.
- Unauthorized users have the IAM permission to lakeformation:PutDataLakeSettings and lakeformation:GetDataLakeSettings.
- Principals have broadly scoped access (e.g., to databases and tables that are beyond the scope of their use case).
- AWS CloudTrail is not enabled.
- Broadly scoped LF-tags auto-provide access to unauthorized principals.
- The default configuration of Lake Formation disables some security controls: https://docs.aws.amazon.com/lake-formation/latest/dg/change-settings.html.
Integrated AWS Services
Amazon Redshift, Amazon Athena, and Amazon EMR
These services allow end users to access data from Lake Formation by using the scoped-down and limited permissions that are granted to their principals. These services mostly work as expected, and a user should be able to access only resources that their principal is restricted to if the proper role is used to call the integrated services.
Some caveats should be considered:
- Lake Formation permissions are enforced only for locations that are registered with Lake Formation. Locations that are not registered can still be accessed if the caller has the underlying IAM permission that is required to do so.
- Callers are required to have the lakeformation:GetDataAccess permission
- In Amazon Athena, query history is not protected by Lake Formation. Sensitive data could be disclosed via query history based on previous requests. This configuration can be controlled via Athena workgroups.
- Query history locations in S3 cannot be registered with Lake Formation
- Amazon EMR integrates with Lake Formation only for the following applications, and if a different application is used for data, it will not enforce Lake Formation permissions:
- EMR Notebooks
- Apache Zeppelin
- Apache Spark through EMR Notebooks
- It is possible to restrict access to specific columns. However, a user can obtain information about a table's properties, so storing and relying on sensitive information inside of table properties or column names is not recommended.
Closing Comments
By employing these techniques, organizations can harden both their AWS Lake Formation security, as well as the supporting data lake environment. For most organizations, Lake Formation is one part of a larger cloud environment and strategy, and it is important to take a wholistic view of cloud security controls across your environment. To get additional help with your AWS Lake Formation or cloud security strategy, visit: Cyber Security Services | Cyber Risk | Kroll


Pratik Amin
Stay Ahead with Kroll
Cyber and Data Resilience
Kroll merges elite security and data risk expertise with frontline intelligence from thousands of incident responses and regulatory compliance, financial crime and due diligence engagements to make our clients more cyber- resilient.
Cloud Security Services
Kroll’s multi-layered approach to cloud security consulting services merges our industry-leading team of AWS and Azure-certified architects, cloud security experts and unrivalled incident expertise.
Threat Exposure Management
Kroll’s field-proven cyber security assessment and testing solutions help identify, evaluate and prioritize risks to people, data, operations and technologies worldwide.
Cyber Risk Retainer
Kroll delivers more than a typical incident response retainer—secure a true cyber risk retainer with elite digital forensics and incident response capabilities and maximum flexibility for proactive and notification services.