
Cyber
March 15, 2019
New Variables and SFTP Support in KAPE v0.8.3.0
The latest version of KAPE (0.8.3.0) is now available and includes several updates. See changelog and explore some of the new features below:
- Added %kapeDirectory% variable that is replaced with the full path to where kape.exe was executed. Useful to have a reference point for config files to pass to modules, etc.
- Added SFTP support. Server name, port and username are required. See help screen for more details and switches. SFTP password, when present, will be redacted from the ConsoleLog.
- Added zip to container options. Works like VHD(x) containers, but compresses files.
- When targeting $J, only copy the non-sparse part of the file. This makes for much smaller (and faster) collection
- Added _kape.cli support. _kape.cli should contain one or more KAPE command lines (one per line). When KAPE sees this file on start up, it executes one copy of KAPE per line in the file, then renames _kape.cli by adding a timestamp to the front of the file. See here for more details and example usage.
- Remove --toe option
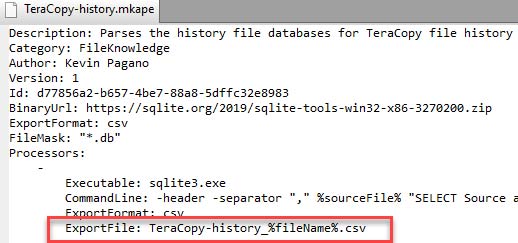
- In modules, for ExportFile property, %fileName% will be replaced with the name of the file being processed. Example: ExportFile: TeraCopy-history_%fileName%.csv
(The full changelog is included in the KAPE package, which you can download here. If you’ve already downloaded KAPE, use the same download link included in the confirmation email.)
New Variables
Two new variables have been added.
First is %kapeDirectory%. This variable will contain the full path to where KAPE was launched. For example, if you ran KAPE from C:\tools\KAPE and referenced %kapeDirectory% in a module’s command line property, it would be replaced with C:\tools\KAPE. This is useful if you have additional configurations or templates for third-party programs and want a way to find them.
The second variable is also for use in modules, but is specific to the ExportFile property. The new variable is %fileName% and this will be replaced with the file name being processed by a module. For example, if your module was looking for ‘main.db’ and KAPE found one to process at C:\temp\tout\C\someDir\main.db, KAPE would replace %fileName% with main.db. It is useful to have the ExportFile property reflect the name of the file where the data came from.
New container option
A new container format, zip, has been added. This works the same as the VHD(X) options in that anything collected by targets ends up in a zip file. The switch for this is --zip
SFTP support
KAPE now supports the transfer of the container formats to an SFTP server. The switches for this feature are:

The required switches are --scs, --scp and --scu. If the --scc switch is not supplied, the computer name where KAPE is running is used. The comment is used when naming the file uploaded to the SFTP server and can be used to help identify where something originated from.
Batch mode configuration
Batch mode works by placing one or more command lines (without the kape.exe part) into a file named _kape.cli. This file should contain one full command line on each line. This allows you to preconfigure KAPE to perform a given action (for example, collect certain files, zip them, then SFTP them to somewhere).
This allows you then run kape.exe as an administrator (or, walking a remote customer/client/person through this process) and KAPE will do what it is told. All they need to do is right click kape.exe and run it as an admin.
For each line in _kape.cli, a new instance of KAPE will start using that line as its arguments.
When all lines in the file have been processed, the initial instance of KAPE renames the file, adding a timestamp to it, and exits. This lets you know when the file was processed and prevents subsequent executions of _kape.cli the next time KAPE is executed.
An example _kape.cli might look like this:

Note that one of the lines ends with --gui. This means that window will stay open for someone to review the output. If you want everything to run and exit, just exclude --gui.
Other changes
$J files can be huge, yet often contain only a few dozen megabytes of actual data. Prior to this release, KAPE would copy $J in its entirety, empty space and all. This means you might end up with a 20 GB file but only 35 MB of data. This slowed things down considerably from a copying and hashing perspective. This version of KAPE only copies the non-sparse sections of $J, making KAPE significantly faster. For example, the previous version took over 300 seconds to process the FileSystem target on some systems, but the new version takes around 30 seconds.
The --toe option (abort on copy error) was removed. The only time KAPE will abort is if it detects an out of disk space condition.
Finally, some additional refinements have been made, such as showing the progress for zipping and file transfers in the title bars.
Get Started
I hope you enjoy the latest release. If you haven’t downloaded KAPE yet, you can do so here; if you’ve already downloaded KAPE, update it as soon as you can to enjoy the new features.

Stay Ahead with Kroll
Cyber and Data Resilience
Kroll merges elite security and data risk expertise with frontline intelligence from thousands of incident responses and regulatory compliance, financial crime and due diligence engagements to make our clients more cyber- resilient.
24x7 Incident Response
Kroll is the largest global IR provider with experienced responders who can handle the entire security incident lifecycle.
Office 365 Security, Forensics and Incident Response
Digital forensic experts investigate hundreds of Office 365 incidents per year and help strengthen your security.
Malware and Advanced Persistent Threat Detection
Our expertise allows us to identify and analyze the scope and intent of advanced persistent threats to launch a targeted and effective response.